Sharon Lin, Analytics Manager @ Twitch and former Data Scientist at Okta on tackling the difficult task of creating a churn prediction model at Okta, the criteria she used, and the models she evaluated.
SHARON LIN, Analytics Manager @ Twitch and former Data Scientist @ Okta on tackling the difficult task of creating a churn prediction model at Okta, the criteria she used, and the models she evaluated:
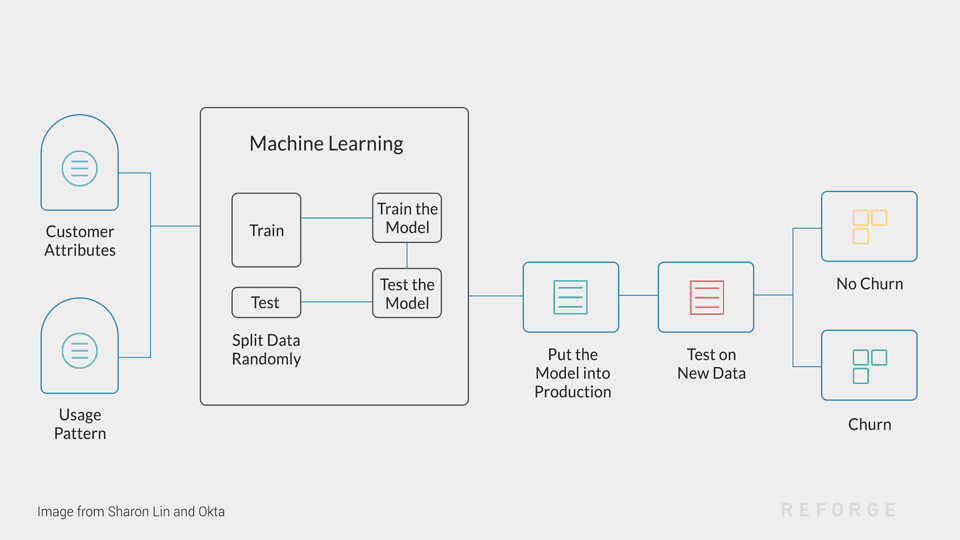
Judging A Churn Model
When choosing from the many models out there to use to predict enterprise churn simple accuracy won’t show the whole picture. Enterprise churn should be under 25%, so simple accuracy isn’t the whole picture. A model that says “no one will churn” will be 75% accurate. So you want to focus on precision and recall.
Precision is the % of all churn that the model correctly identifies
Recall is the % of identified churn that actually ends up churning
These evaluate false positives, which lead to unnecessary and costly churn prevention efforts, and false negatives, which lead to companies churning without being identified.
The Classification Models (Supervised)
Churn prediction is typically treated it as a classification problem, classifying a customer as yes/no for churning.
Logistic Regression is an easy starting point. It’s easy to explain and implement, so it’s an easy sell. Behind many large companies' ML is just simple logistic regression.When there's so much data (like online advertising) logistic regression can train your model very quickly. But as an enterprise company with only thousands of data points, there may not be enough data to get very good results.
Naive Bayes is typically used with text classification and it performs well when solving for multiple classes. Instead of simply giving yes/no, it can classify customers as low/medium/high risk. But after slicing the dataset into training and testing data for each individual class you still might not have enough data to get good results.
Random Forest can yield good results with less data, so it’s one of the best classification models for churn prediction. And it might be perfect if you're using raw data, but it’s critical weakness is that it does not handle dynamic data as well. It has trouble with data like “customer usage over the last 30 days,” which is constantly changing.
The Anomaly Models (Unsupervised)
Because enterprise churn is a rare event, it’s worth treating it as an anomaly and testing models build for anomaly detection.
Multivariate Gaussian Distribution is often used for security, like identifying DDOS attacks. It works best when the anomalies happen in the same way. This isn’t an ideal model if enterprise customers are churning for many different reasons.
**Clustering **is good at identifying different groups of companies. Depending on the data it uses, it can group by useful churn indictors or something useless, like the color of the companies’ logo.
Each model will have different strong points and how it will perform depends on the data that it uses and the churn behavior of your customers. In the enterprise, this is a particularly difficult problem because there’s bound to be fewer data points. Test different models and find which yields the best precision and recall to identify and help prevent churn.
Summarized by Reforge. Original article by Sharon Lin • Analytics Manager @ Twitch